Project Overview
The Temu Extension is a sophisticated Chrome extension developed for GoCabi LLC, a USA-based client, designed to automate the process of extracting, analyzing, and organizing product data from the Temu marketplace. This powerful tool was created to address the growing need for efficient market research, competitive analysis, and data-driven decision-making in the e-commerce sector. Published on the Chrome Web Store, this extension serves businesses, researchers, and e-commerce professionals who require comprehensive product information at scale.
The project involved extensive work with Chrome Extension APIs, web scraping technologies, data parsing algorithms, and real-time extraction mechanisms. As a freelance developer working remotely for a Wyoming-based client, I was responsible for the complete development cycle including requirements gathering, architecture design, implementation, testing, and deployment to the Chrome Web Store. The extension demonstrates advanced capabilities in handling dynamic web content, processing large datasets, and providing users with clean, structured data ready for analysis.
Key Features
- Real-Time Data Extraction: Engineered a sophisticated scraping engine that extracts product information in real-time as users browse Temu marketplace. The extension automatically detects product pages and initiates data extraction without requiring manual intervention, providing seamless integration into the user's browsing workflow.
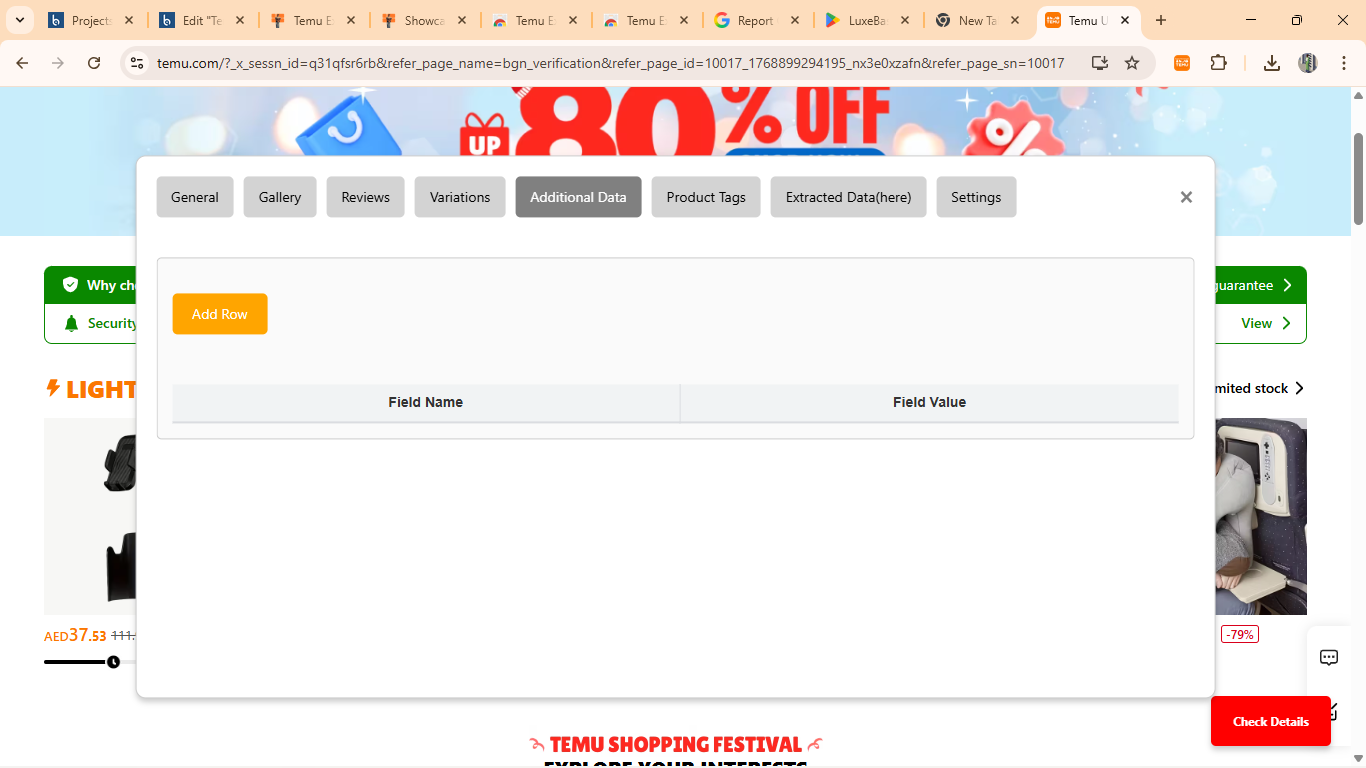
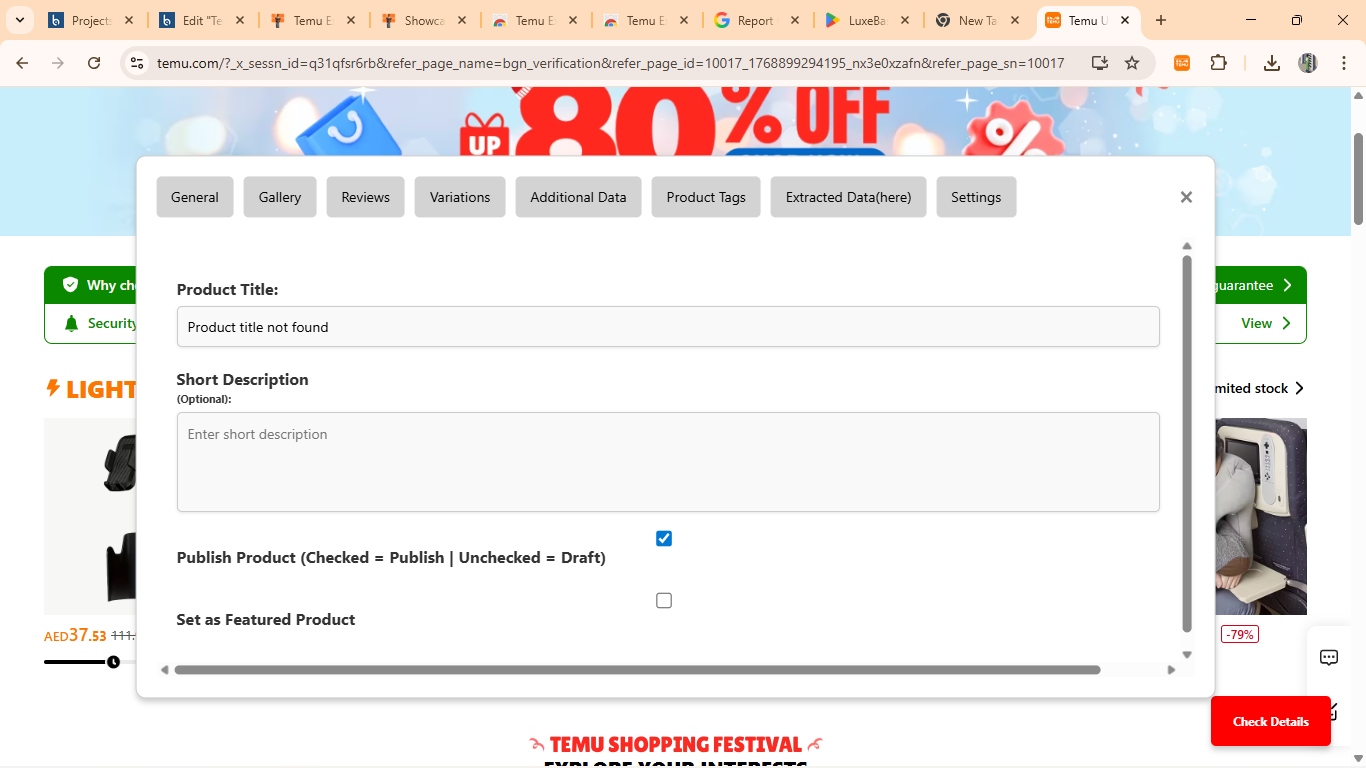
- Comprehensive Product Data Collection: Captures extensive product details including product titles, descriptions, pricing information (regular price, sale price, discount percentages), seller information, product ratings and reviews, number of units sold, shipping details, product specifications, variant options (colors, sizes, models), product images and galleries, SKU numbers, category classifications, and availability status. This comprehensive data collection ensures users have all necessary information for thorough market analysis.
- Intelligent Data Parsing: Implemented advanced parsing algorithms that handle various data formats, clean inconsistent data entries, normalize pricing across different currencies, extract relevant information from unstructured text, handle special characters and internationalization, and structure data into consistent, usable formats. The parsing engine is robust enough to handle edge cases and data anomalies commonly found in web scraping scenarios.
- Bulk Extraction Capabilities: Developed functionality to extract data from multiple products simultaneously, allowing users to gather information from entire category pages, search result listings, or custom product collections. The bulk extraction feature includes progress tracking, pause and resume capabilities, and error recovery mechanisms to ensure reliable operation even with large datasets.
- Advanced Filtering and Search: Integrated smart filtering options allowing users to extract products based on specific criteria such as price ranges, rating thresholds, seller types, shipping options, discount percentages, and category selections. This targeted extraction saves time and ensures users collect only the most relevant data for their specific needs.
- Data Export Functionality: Implemented multiple export formats including CSV (Comma-Separated Values) for spreadsheet analysis, JSON for programmatic data processing, Excel (.xlsx) with formatted sheets and headers, and PDF reports with visualizations and summaries. Users can customize export settings including field selection, data sorting, and formatting preferences.
- Real-Time Price Monitoring: Created a price tracking feature that monitors selected products and alerts users when prices change, drop below specified thresholds, or when special promotions become available. This feature is particularly valuable for competitive pricing strategies and deal hunting.
- Data Visualization Dashboard: Built an intuitive dashboard within the extension popup that displays extracted data in organized tables, charts showing price distributions and trends, statistics about scraped products, quick filters for data refinement, and export options readily accessible. The dashboard provides at-a-glance insights without leaving the browser.
- Batch Processing Queue: Implemented a queue management system that handles multiple scraping tasks simultaneously, prioritizes tasks based on user preferences, manages rate limiting to avoid detection, handles retries for failed requests, and provides detailed logs of extraction activities.
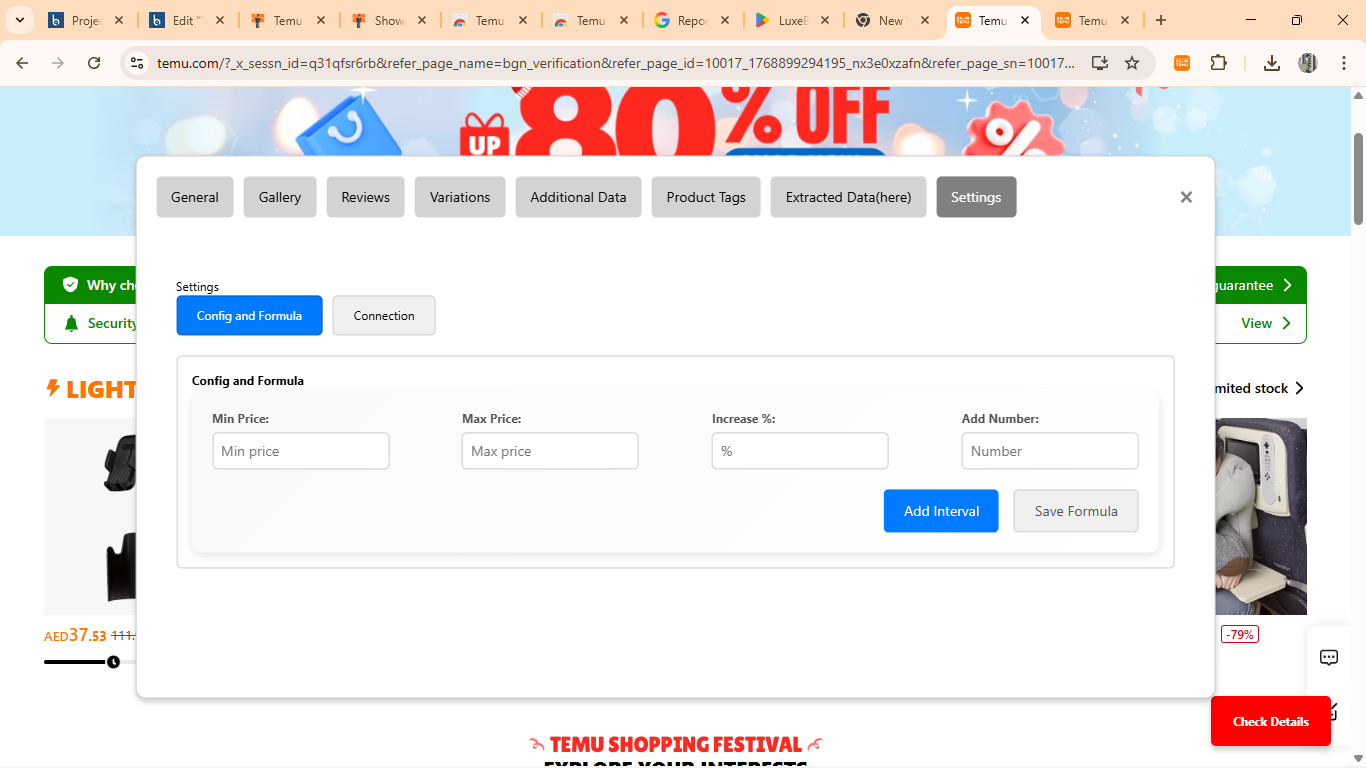
- Custom Data Templates: Developed a template system allowing users to define custom data extraction patterns for specific use cases, save frequently used extraction configurations, share templates with team members, and adapt to changes in website structure through template modifications.
- Browser Storage Integration: Utilized Chrome's local storage APIs to cache extracted data, save user preferences and settings, maintain extraction history, and enable offline access to previously collected data. Implemented efficient storage management to prevent excessive memory usage.
Technologies Used
Chrome Extension APIs: Leveraged extensive Chrome Extension APIs including chrome.tabs for browser tab management and navigation, chrome.storage for persistent data storage, chrome.runtime for background script communication, chrome.scripting for content script injection, chrome.downloads for automated file downloads, chrome.notifications for user alerts, and chrome.contextMenus for right-click functionality. Mastered the manifest V3 architecture ensuring compliance with latest Chrome extension standards and security requirements.
Web Scraping Technologies: Implemented advanced web scraping techniques using JavaScript DOM manipulation for direct element access, CSS selectors for precise element targeting, XPath expressions for complex element queries, mutation observers for detecting dynamic content changes, and AJAX interception for capturing API responses. Developed custom scraping logic that adapts to Temu's dynamic content loading and handles various page layouts.
Data Parsing Libraries: Utilized parsing libraries and custom algorithms for HTML parsing and cleanup, JSON data extraction from embedded scripts, regular expressions for pattern matching, data validation and sanitization, type conversion and normalization, and character encoding handling. Implemented robust error handling to manage malformed data gracefully.
Asynchronous Programming: Employed modern JavaScript async/await patterns for clean asynchronous code, Promise chains for sequential operations, Promise.all for parallel processing, error handling with try-catch blocks, and timeout management for network requests. This ensures responsive user interface and efficient background processing.
Data Export Mechanisms: Integrated libraries for CSV generation with proper escaping and formatting, JSON serialization with customizable indentation, Excel file creation using SheetJS library, Blob API for file creation, and URL.createObjectURL for download triggers. Implemented compression for large datasets to optimize file sizes.
Background Processing: Designed efficient background scripts using service workers (Manifest V3), message passing between components, long-running task management, resource cleanup and memory management, and persistent storage for task queues. This architecture ensures the extension remains performant without impacting browser speed.
User Interface Development: Built the extension's user interface using HTML5 semantic markup, CSS3 for styling and animations, responsive design for different popup sizes, Bootstrap components for consistent UI elements, and vanilla JavaScript for interactive features. The UI is clean, intuitive, and provides excellent user experience.
API Integration: Connected with third-party services for currency conversion, data enrichment services, cloud storage options (Google Drive, Dropbox), and analytics tracking. These integrations expand the extension's capabilities and provide additional value to users.
Security Implementation: Implemented content security policies (CSP), input sanitization to prevent XSS attacks, secure data storage with encryption, permission management following principle of least privilege, and secure communication between extension components. Security was a top priority throughout development.
Technical Architecture
- Background Service Worker: Manages long-running scraping tasks, handles API requests and rate limiting, coordinates between different extension components, maintains extension state and data persistence, and executes scheduled tasks and monitoring operations.
- Content Scripts: Inject into Temu product pages to access DOM elements, extract visible product information, monitor dynamic content loading, communicate with background scripts, and provide real-time feedback to users through page overlays.
- Popup Interface: Serves as the main user interaction point with dashboard displaying scraped data, controls for starting/stopping extraction, filter and export options, settings and configuration panel, and help documentation and tutorials.
- Storage Layer: Manages local storage for cached data and user preferences, sync storage for cross-device settings synchronization, IndexedDB for large dataset storage, and cleanup routines to prevent storage overflow.
Design Highlights
- User-Friendly Interface: Created an intuitive, easy-to-navigate interface that requires minimal learning curve. Users can start extracting data within minutes of installation without extensive technical knowledge. The design follows familiar patterns from popular productivity extensions to reduce friction.
- Performance Optimization: Optimized the extension for minimal resource consumption, ensuring it doesn't slow down browser performance. Implemented efficient DOM queries, throttling and debouncing for event handlers, lazy loading for large datasets, and memory leak prevention through proper cleanup.
- Error Handling and Resilience: Built comprehensive error handling throughout the extension including graceful degradation when scraping fails, informative error messages for users, automatic retry mechanisms with exponential backoff, logging for debugging and support, and recovery from unexpected website changes.
- Responsive Design: Ensured the popup interface works well across different screen sizes and resolutions, adapts to Chrome's dark mode theme, maintains readability with proper typography and spacing, and provides clear visual hierarchy for information.
- Customization Options: Provided users with extensive customization including extraction field selection, export format preferences, scheduling options for automated scraping, notification settings, and theme customization for the dashboard.
Technical Challenges and Solutions
- Dynamic Content Loading: Temu marketplace uses dynamic content loading and infinite scroll. Solved this by implementing mutation observers to detect new content, scroll automation for paginated results, and waiting strategies to ensure all content loads before extraction.
- Anti-Scraping Measures: Addressed rate limiting and bot detection by implementing request throttling, randomized delays between requests, user-agent rotation, and session management to mimic natural browsing patterns while staying within ethical scraping boundaries.
- Data Consistency: Handled inconsistent data formats across different product types by creating flexible parsing templates, implementing fallback extraction methods, normalizing data structures, and validating extracted information against expected schemas.
- Large Dataset Management: Optimized handling of large datasets through chunked data processing, streaming exports for large files, pagination in the dashboard, and automatic data archiving to prevent performance degradation.
- Cross-Browser Compatibility: While primarily developed for Chrome, ensured the extension architecture allows for potential Firefox and Edge compatibility through standardized WebExtension APIs and minimal Chrome-specific dependencies.
Chrome Web Store Publication
Successfully published the extension on Chrome Web Store under GoCabi LLC's developer account. The publication process included creating compelling extension description and promotional copy, designing eye-catching icons and screenshots, implementing required permissions with clear justifications, passing Chrome Web Store review process, implementing analytics to track usage and performance, and maintaining the extension with regular updates based on user feedback.
Use Cases and Applications
- Market Research: E-commerce businesses use the extension to analyze competitor pricing strategies, identify trending products and categories, discover new product opportunities, and track market dynamics and seasonal changes.
- Price Comparison: Retailers and consumers leverage the tool to compare prices across similar products, track historical pricing trends, identify the best deals and discounts, and monitor competitor pricing in real-time.
- Inventory Planning: Sellers utilize extracted data to identify fast-moving products, analyze product variant performance, plan inventory based on demand indicators, and discover profitable product niches.
- Competitive Analysis: Marketing teams analyze competitor product catalogs, study product descriptions and positioning, track new product launches, and benchmark pricing and promotional strategies.
- Academic Research: Researchers collect e-commerce data for market studies, analyze consumer behavior patterns, study pricing dynamics, and investigate marketplace trends.
Client & Impact
Client: GoCabi LLC, Wyoming, USA
Project Type: Freelance Chrome Extension Development
Duration: Custom project completed and maintained with ongoing updates
Impact: The Temu Extension has become a valuable tool for e-commerce professionals and market researchers, significantly reducing the time and effort required to collect comprehensive product data from Temu marketplace. Users report saving dozens of hours weekly on manual data collection tasks. The extension has enabled data-driven decision-making for pricing strategies, product selection, and competitive positioning. The automated extraction capabilities have allowed businesses to scale their market research operations without proportionally increasing headcount or costs.
The client was extremely satisfied with the extension's reliability, comprehensive feature set, and professional implementation. The project demonstrated expertise in complex web scraping scenarios, Chrome extension development, and delivering production-ready tools that solve real business problems. Positive user reviews on the Chrome Web Store validate the extension's utility and quality.
Personal Development and Learning
This project significantly expanded my technical expertise in Chrome Extension development, advancing my understanding of browser APIs and extension architecture. I gained deep knowledge of web scraping techniques, including handling dynamic content, anti-scraping measures, and data extraction from complex web applications. The project enhanced my skills in asynchronous JavaScript programming, data parsing and transformation, and building user-friendly interfaces for technical tools.
Working with a USA-based client remotely improved my communication skills, project management abilities, and understanding of client expectations in international markets. The experience of publishing on Chrome Web Store taught valuable lessons about app store optimization, user acquisition, and maintaining public-facing software products.
Security and Ethics Considerations
Throughout development, I maintained strict adherence to ethical scraping practices including respecting robots.txt directives, implementing reasonable rate limiting, not overloading target servers, collecting only publicly available information, and following Chrome Web Store policies and guidelines. The extension includes clear terms of use and educates users about responsible data collection practices.